Contrastive Language-Image Pre-training
Contrastive Language-Image Pre-training (CLIP)
参考链接
概述
什么是CLIP? 一种基于对比文本-图像对的预训练方法或者模型。
任务:通过对比学习的方式,实现一张图像和他对应的文本描述的匹配
训练:有监督对比学习
包括两个模型:
- Text Encoder
- 用来提取文本的特征,可以采用NLP中常用的text transformer模型
- Image Encoder
- 来提取图像的特征,可以采用常用CNN模型或者vision transformer
主要流程

步骤
Contrastive pre-training
对于一个包含
对角线上的
Cosine Similarity
通常用于衡量两个高维向量之间的相似性,如文本挖掘和数据挖掘等。
模型选择
- Image Encoding
考虑了2个模型: ResNet和Vision Transformer(ViT)
ResNet
ResNet: 残差网络
是一种经典的CNN神经网络
(注意区别RNN, Recurrent Neural Network)
Reference: https://zh.d2l.ai/chapter_convolutional-modern/resnet.html
首先,假设有一类特定的神经网络架构
对于所有
现在假设
相反,我们将尝试找到一个函数
例如,给定一个具有
那么,怎样得到更近似真正
唯一合理的可能性是,我们需要设计一个更强大的架构
换句话说,我们预计
然而,如果
事实上,
对于非嵌套函数(non-nested
function)类,较复杂的函数类并不总是向“真”函数
左边,虽然
相反, 对于右侧的嵌套函数(nested function)类

因此,只有当较复杂的函数类包含较小的函数类时,我们才能确保提高它们的性能。 对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)
所以,ResNet设计出了一个残差块(右),相比正常块,残差块需要拟合出残差映射

Vision Transformer
Vision Transformer (ViT)
Reference: https://blog.csdn.net/fulva/article/details/121045938
https://arxiv.org/abs/2010.11929

目标:把词结构转化为图结构
把图片分割成一个一个Patch,每个Patch相当于句子中的一个词。Patch Embedding就是再把Patch再经过一个全连接网络压缩成一个具有一定维度的向量。
接下来,需要在embedding中添加位置信息。通过固定算法/训练获得的信息产生的位置向量直接加上patch embedding.
Attention
- Text Encoder
经典的transformer结构
Zero-shot
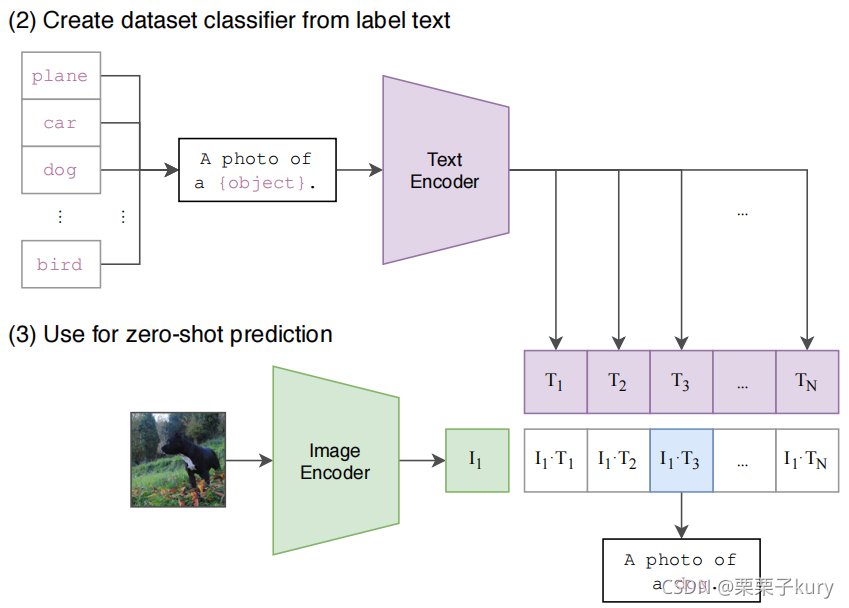
Prompt Engineering
- 输入:一张图片 + 所有类别转换的文本(100个类别就是100个文本描述)。
- 计算图像的特征嵌入和由它们各自的编码器对可能的文本集的特征嵌入。
- 计算这些嵌入的cosine similarity,用温度参数
进行缩放,并通过softmax归一化为概率分布。
根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为
- Title: Contrastive Language-Image Pre-training
- Author: Yuze-L
- Created at : 2024-07-31 21:23:10
- Updated at : 2024-08-01 15:55:27
- Link: https://yuze-l.github.io/2024/07/31/CLIP/
- License: This work is licensed under CC BY-NC-SA 4.0.