Generative Adversarial Networks
GAN
论文链接:https://arxiv.org/abs/1406.2661
Generative Adversarial Networks
同时训练两个模型:
- Generative Model (
) that captures the data distribution - Discriminant Model (
) that estimates the probability that a sample came from the training data rather than
为了学习generator对于数据
同理,
具体算法

conditional GAN
参考链接:https://zhuanlan.zhihu.com/p/618066889
我们无法控制GAN的输出类型。为了让输出可控,我们可以增加一个额外的输入标签作为指导条件(也就是
在cGAN中,指导条件(称作
pix2pix
本质上pix2pix也是一种特殊的cGAN
对应的任务是image-to-image translation(色彩填充、轮廓标签、填充生成等)
输入的图像是一个高维的向量,因此我们的G不只是一个简单的解码器,而是Encoder-decoder的一个结构。最常用的就是U-Net
U-Net
https://zh.wikipedia.org/wiki/U-Net
一种卷积神经网络,可以用更少的训练图像产生更精确的分割。
在传统的encoder-decoder基础上增加了skip-connection结构,将encode过程中卷积得到的不同尺寸的特征图,直接concatenate到decode过程中相应尺寸的特征图上,这样避免了一些特征在下采样过程中的损失,尽可能的保留了原始图像在不同尺寸上的特征信息。
所以,输入给判别器
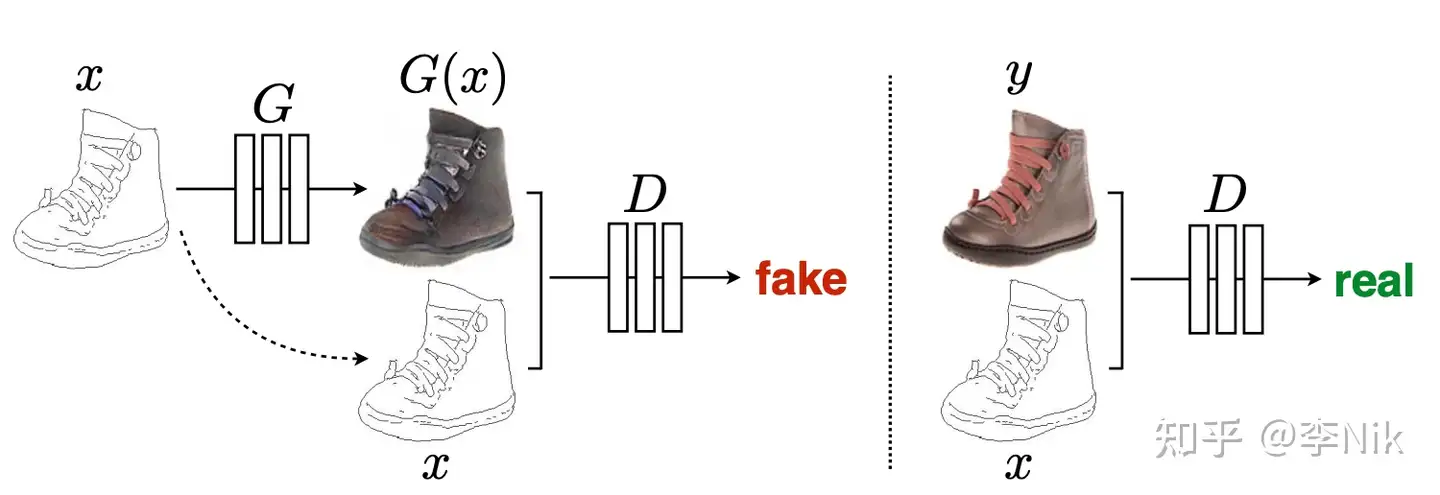
还有一个问题,采用encoder-decoder的结构的生成器训练完成后模型参数不再发生变化,那么输入图像对应的输出是唯一确定的。所以,我们需要引入服从标准正态分布的随机向量
但是cGAN的随机性不是特别好.
pix2pix模型的损失函数除了上面的
单独使用L1或者L2都会导致结果更加偏向模糊,这是因为这两种损失函数均是对对应像素差取均值,这样的话会使得输出的像素分布更加平缓,从而只能很好的保留低频信息,却无法生成准确的高频信息
PatchGAN
原来我们对于生成的图片只有一个True/False,但是通过PatchGAN,我们将原始图片通过卷积称为
区别
参考:https://sahiltinky94.medium.com/understanding-patchgan-9f3c8380c207
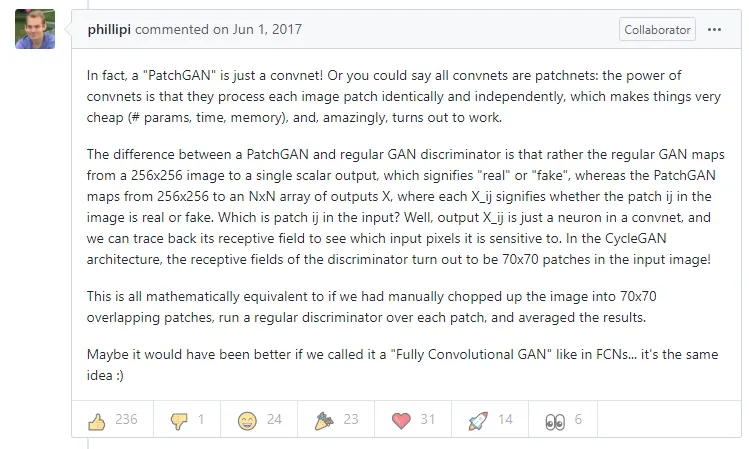
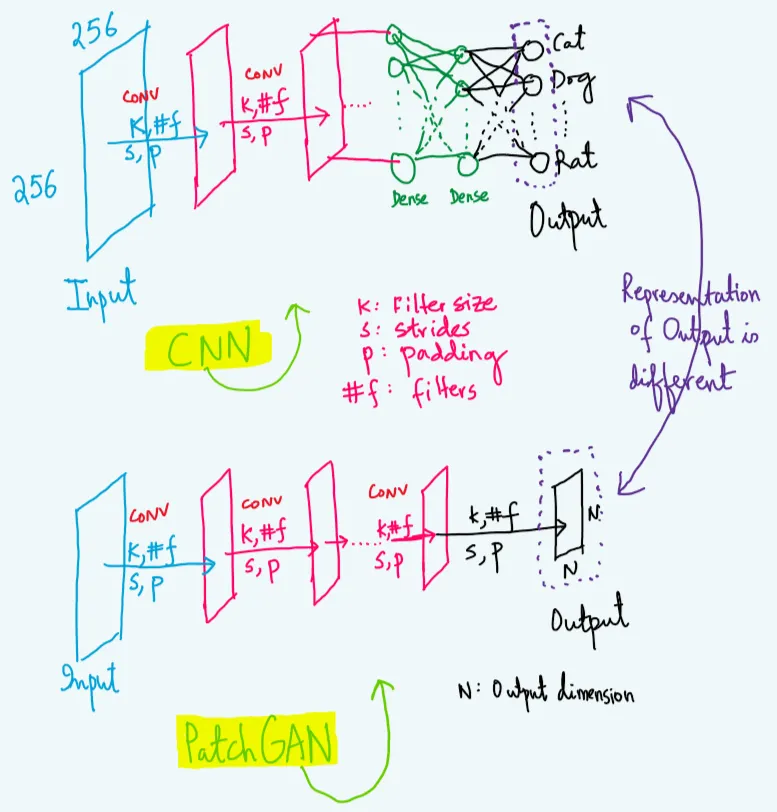
CNN将一张输入图像输入网络后,会给出整个输入图像大小属于标量向量的概率。
然而,在PatchGAN中,在将一张输入图像输入网络后,它会给出
尝试实操
https://www.tensorflow.org/tutorials/generative/pix2pix?hl=zh-cn
可以训练 但是不想训练了()
- Title: Generative Adversarial Networks
- Author: Yuze-L
- Created at : 2024-07-31 14:54:58
- Updated at : 2025-06-28 23:29:42
- Link: https://yuze-l.github.io/2024/07/31/GAN/
- License: This work is licensed under CC BY-NC-SA 4.0.